Baekjoon Online Judge (BOJ)는 온라인 저지로 프로그래밍 문제를 온라인으로 채점받을 수 있는 사이트입니다.
2010년 3월 19일 운영을 시작해서 글의 작성 시점을 기준으로 9년 반이 되었습니다.
이 글에서는 지난 10년간 사이트의 구조가 어떻게 변했고, 왜 변했는지를 알아보려고 합니다. 이전 글과 겹치는 부분 또는 다른 부분도 있습니다.
다음 3가지를 꼭 기억하면서 이 글을 읽어주세요.
- 2010년부터의 내용을 담고 있어서 기억과 순서의 오류가 발생할 수 있습니다.
- 2010년부터의 내용이기 때문에 현재와는 다른 결정을 한 부분이 있습니다.
- 2010년부터 코딩 실력이 상승해서 이전에는 실력 부족으로 할 수 없었던 일을 현재는 할 수 있게 된 경우도 있습니다.
채점의 신뢰성은 다음과 같은 의미를 갖습니다.
- 같은 소스를 여러 번 제출해도 결과는 같아야 한다.
2010년

첫 모습입니다. 오픈 소스 프로젝트 hustoj를 이용해서 실행을 시켰습니다. 당시 hustoj는 github도 아닌 Google Code를 사용했습니다. 현재와는 기능도 다르며, 거의 모든 것이 다르다고 생각되는 오픈소스 프로젝트입니다.
당시 hustoj는 싱글 서버에서 운영하기 좋게 되어있었습니다. 추후에는 프로젝트에 여러가지 기능이 추가되었습니다.
2010년에는 사이트의 기능보다는 컨텐츠(문제)를 확보하는데 주력했습니다. 이 당시 채점 프로그램의 모습을 간단하게 그려보면 아래와 같습니다.
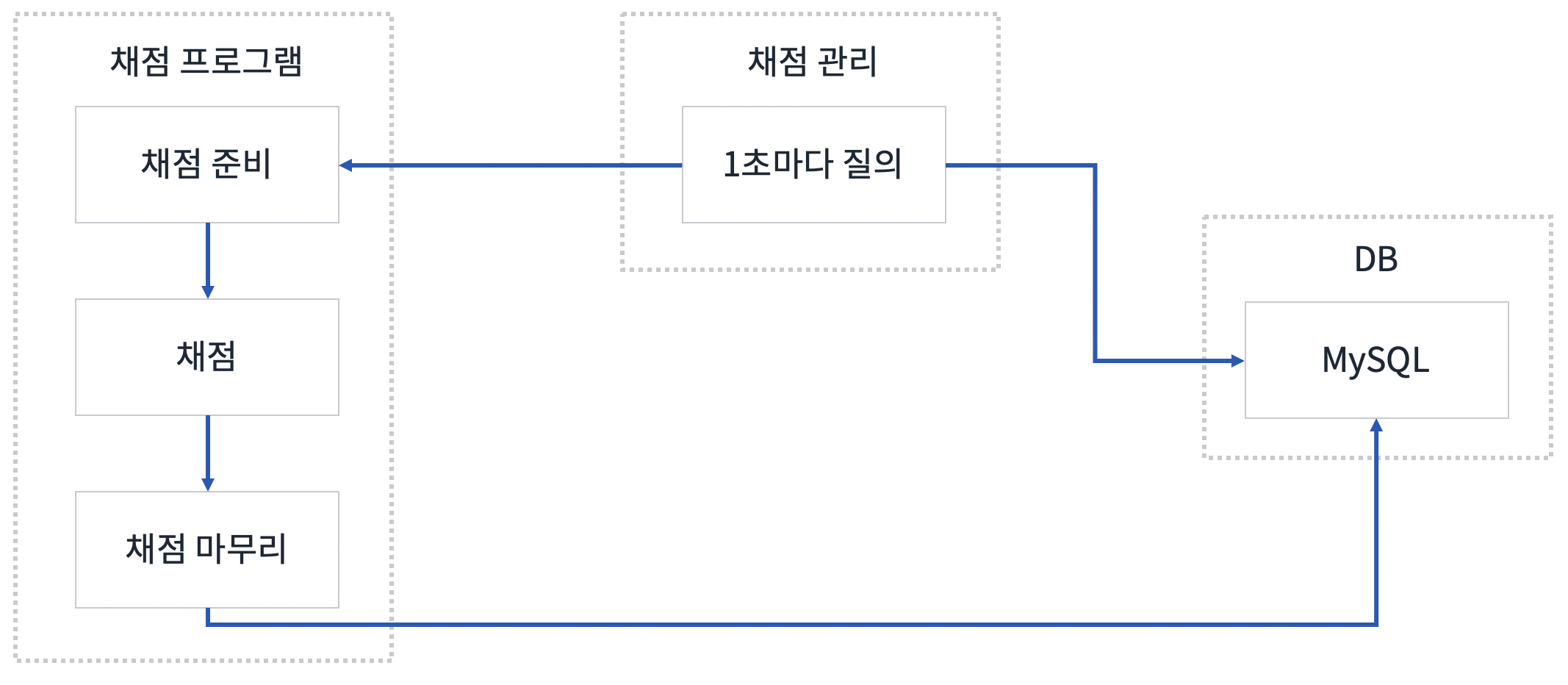
채점 프로그램은 총 2개로 구성 되어있는데, 채점 관리와 채점 프로그램입니다.
채점 관리는 DB에서 채점해야 하는 소스를 1초마다 한 번씩 쿼리로 검색하는 역할을 담당하고, 채점 프로그램을 실제로 채점하는 역할을 담당합니다.
2012년
2012년에 BOJ의 전체 소스 코드(웹, 채점)를 다시 작성하게 되었습니다. MVC패턴을 이용해서 프레임워크를 사용하지 않고 직접 프레임워크 역할을 하게 코드를 구현했습니다.
이때 hustoj 프로젝트 오너에게 이 사실을 알렸고 독립하고 라이센스를 지워도 된다는 확인을 받았습니다. 이제부터는 오픈소스 프로젝트에서 벗어나게 되었습니다.
당시 BOJ에 이것저거 개발을 하다보니 정기적으로 실행해야 하는 기능이 생겼습니다. 대표적으로 Topcoder 레이팅 업데이트와 문제 순위 업데이트가 있었습니다.
주기를 가지고 실행하는 방법을 고민해보던 중에 crontab을 이용하기로 결정했고, 아래와 같은 그림을 가지게 되었습니다

채점 서버 2대
유저와 제출이 점점 증가했고, 채점 서버를 1대에서 2대로 늘려야 했습니다.
채점 서버를 2대로 늘리면 다음과 같은 상황이 발생할 수 있습니다.
- 채점 관리가 1초에 1개씩 채점해야 하는 채점 번호를 요청하기 때문에, 같은 소스를 채점하는 일이 벌어질 수 있음
위와 같은 일을 막으려면 DB에 락을 걸거나, 메시지 큐를 사용하는 방안이 있습니다. 하지만, 당시에는 DB에 락을 거는 것과 메시지 큐를 사용하는 것을 몰랐기 때문에, 채점 서버를 홀/짝으로 나누기로 했습니다.
채점 서버 (홀수)는 채점 번호가 홀수인 제출만 채점을 하고, 채점 서버 (짝수)는 짝수인 제출만 채점하게 됩니다.

홀/짝으로 채점 서버를 나눈 상황에서는 다음과 같은 일이 벌어졌습니다.
- 홀수 채점 서버가 시간이 오래 걸리는 제출을 채점하고 있어, 뒤쪽의 모든 홀수 채점이 채점을 기다리고 있음
- 짝수 채점 서버에는 운이 좋게 시간이 오래 걸리는 제출이 없음
- 채점 번호가 홀수인 유저들이 짝수가 될때까지 다시 제출하기 시작함
제출이 많아짐을 대비하기 위해서 채점 서버를 늘렸지만, 위와 같은 일로 더욱 제출은 많아지게 되었고, 다른 대안이 필요하게 되었습니다.
데이터 동기화
채점 서버가 2개가 되었기 때문에, 두 채점 서버가 같은 데이터를 이용해 채점하게 데이터 동기화 작업을 거쳐야 합니다.
채점 서버가 1대일 때는 채점 서버에 데이터를 업로드했는데, 이걸 2대일 때 하면 작업이 2배가 되고 사람이 직접 하는 일이라 깜빡하고 실수를 할 수도 있습니다. 따라서, 채점 서버 하나에 올리고 rsync를 이용해 동기화를 진행하기로 했습니다.
이 방법은 다음과 같은 일이 벌어져 채점의 신뢰를 무너뜨릴 수 있습니다.
- 동기화가 되기 전에 제출을 2번해 서로 다른 결과를 받을 수 있음
- 동기화가 되는 중에 제출을 해 이상한 결과를 받을 수 있음
위와 같은 일을 방지하기 위해서는 문제의 제출을 막고 데이터를 업데이트하는 과정이 필요합니다. 하지만, 유저가 적어 새벽 시간을 이용해 동기화를 진행해 위와 같은 일은 벌어지지 않았습니다.
채점 서버 3대
유저와 제출이 더욱 많아졌고, 이제는 채점 서버 3대가 필요하게 되었습니다.
1대에서 2대가 될 때 홀/짝을 사용했으니 3대가 되면 3으로 나눈 나머지를 사용하면 되지만, 그렇게 하지 않았습니다.
제출 언어의 통계를 보면 당시에는 C/C++이 약 80%를 차지하고 있었습니다. 또, C/C++의 수행 시간과 Java, Python의 수행 시간을 비교해보면 C/C++이 매우 빨랐습니다.
당시에는 Java의 제출이 오래걸려 뒤쪽의 제출이 밀리는 현상이 발생했습니다. 이 현상이 위에서 언급한 홀/짝 방식의 단점이 자주 등장하는 계기가 되었습니다. 따라서, 채점 서버를 다음과 같이 3가지로 나누기로 했습니다.
- C/C++ 채점 서버 (홀수)
- C/C++ 채점 서버 (짝수)
- 나머지 언어 채점 서버
사이트의 대부분 유저가 C/C++이기 때문에, 홀/짝이 밀리는 일은 자주 일어나지 않았지만, Java나 Python 유저는 매우 오래 기다려야 하는 단점이 있었습니다.

대회
Coder’s High 2015 Side Contest에서 끔찍한 일이 벌어졌습니다. 한 유저가 시간이 매우 오래걸리는 소스를 지속적으로 제출했습니다.
한 유저가 데이터가 500개이고, 시간 제한이 약 1초인 문제에 0.8초가 걸리는 소스를 10초에 한 번씩 제출했습니다. 채점하는데 약 6분정도 걸리니 대회에 집중된 채점을 처리할 수가 없었습니다.
대회 제출을 빠르게 처리하기 위해서 다음과 같이 채점 서버를 나누었습니다.
- C/C++ 채점 서버 (홀수)
- C/C++ 채점 서버 (짝수)
- 나머지 언어 채점 서버
- 대회 전용 채점 서버 (홀수)
- 대회 전용 채점 서버 (짝수)
AWS로 이주
채점 서버를 AWS로 이주하기로 결정한 것은 2015년이고, 아래와 같은 두 가지 이유 때문에 결정했습니다.
- 새로운 채점 서버를 켜기 위해서 번거로운 과정을 거치지 않아도 됨
- SQS를 사용하고 싶음
사실 SQS는 AWS의 밖에서도 사용할 수 있지만, 당시에는 그걸 몰랐습니다. 가장 큰 이유는 1번 이유이기 때문에 고민할 필요 없이 이주를 시작하게 되었습니다.
이전에는 새로운 채점 서버를 켜는 과정은 매우 힘들었습니다.
- 호스팅 회사 홈페이지에서 새로운 서버 결제
- 세팅이 되길 기다림 (세팅비도 받음)
- 새로운 채점 서버를 세팅함
- 운영중인 모든 채점 서버를 중단함
- 채점 프로그램을 재컴파일 또는 재시작함 (홀/짝이나 이런 옵션을 변경해야 하기 때문)
- 새로운 채점 서버를 시작함
AWS를 이용해 홈페이지에서 클릭만으로 채점 서버를 켤 수 있게 되었습니다.
AWS에는 수많은 인스턴스가 있고, 채점 서버로 사용할 인스턴스를 골라야 합니다. 채점 서버는 다음과 같은 요구사항을 지켜야 합니다.
- CPU는 1코어도 충분 (멀티 코어 프로그래밍을 하는 문제는 없기 때문)
- RAM은 4기가 정도는 되어야 함
t2, m4, c4 중 하나를 사용하기로 결정했는데, t2는 가격이 매우 싸다는 장점이 있지만, 버스트 기능이 있어서 탈락했습니다. CPU가 버스트 되었을 때와 되지 않았을 때의 채점 결과가 다를 수 있기 때문입니다.
항상 일관된 성능을 보여주는 m4, c4 중 하나를 선택하기로 했고, c4를 선택했습니다.
채점 서버는 스팟 인스턴스를 사용해 가격을 매우 절약할 수 있게 되었습니다.
SQS를 사용해 채점 서버의 홀/짝 구분을 없앴고, 아래와 같은 사이트 구조를 가지게 되었습니다.
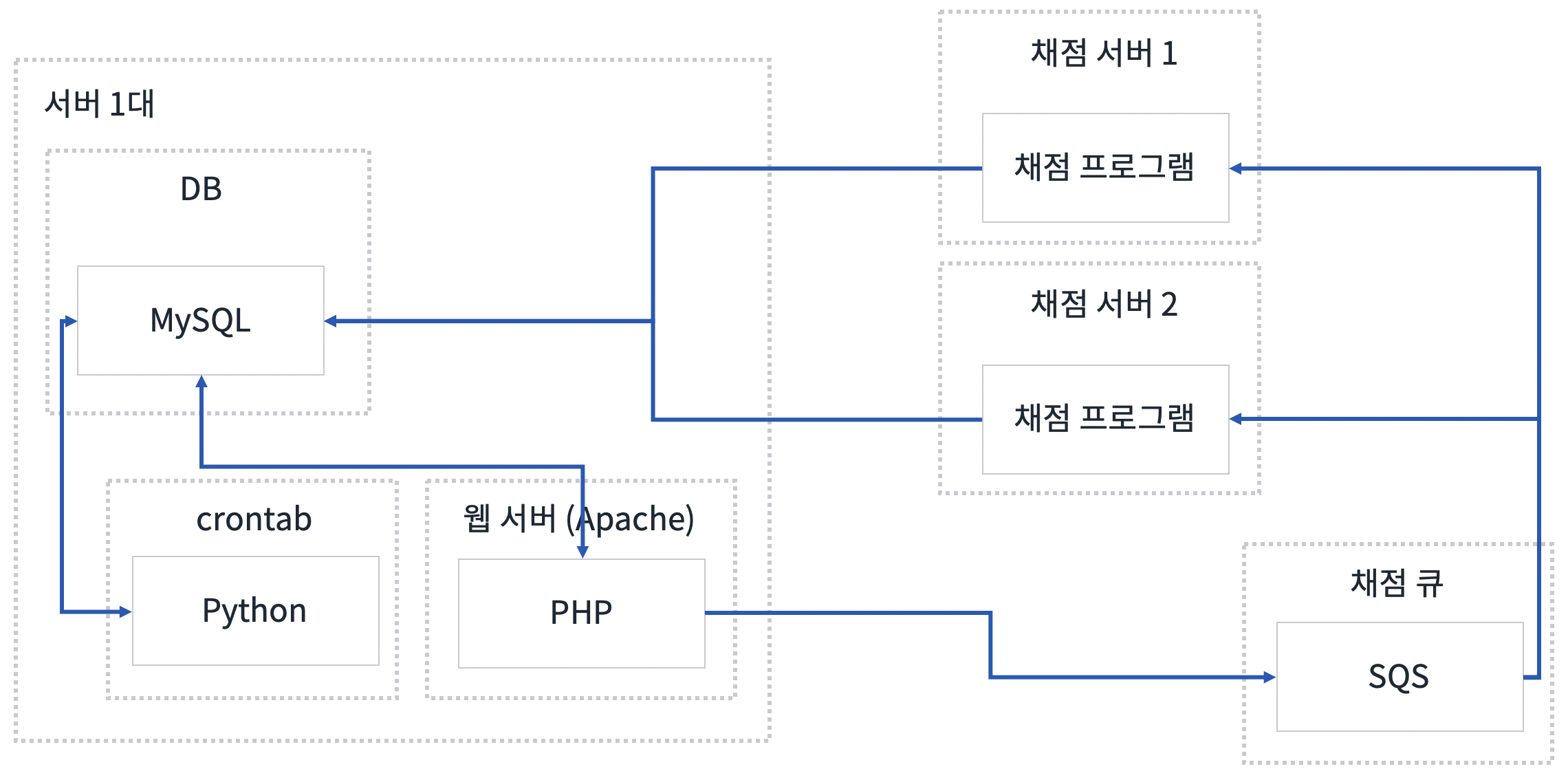
SQS는 FIFO를 사용해 먼저 제출한 사람의 소스를 먼저 채점하게 했습니다. 이제 위에서 언급한 홀/짝 문제는 모두 해결하게 되었습니다. 하지만, 데이터의 동기화와 관련된 문제는 해결되지 않았습니다.
아래 2가지를 모두 해결할 방법을 고민하기 시작했습니다.
- 위에서 언급한 데이터 동기화와 관련된 문제
- 채점에는 실제로 반영하지 않고 단순 테스트 목적인 경우의 채점을 하고 싶음
이 방법을 해결하기 위해 채점을 하지 않는 채점 서버를 추가하기로 했습니다.
아래 그림은 웹과 DB 서버도 AWS로 옮긴 이후입니다.

위의 고민에서 2번 고민은 채점 서버 (메인)에서 채점을 하는 것으로 해결했고, 1번 고민은 다음과 같이 해결했습니다.
- 채점 서버 (메인)의 AMI를 생성 (2-3분)
- 새로운 채점 서버를 켜고 기존 채점 서버를 모두 종료함 (1-2분)
예전과 다르게 직접 서버를 켜고 끌 수 있기 때문에 이런 방식이 가능하게 되었습니다. 나중에 알고보니 이 방식의 배포를 Blue-Green Deployment라고 하는 것을 발견했습니다.
2부
2부에서는 채점 프로그램의 속도를 향상시키기 위한 노력들을 알아봅니다.

“BOJ 10 Years 1부”에 대한 답글 3개