BOJ 10 Years 1부에서 이어지는 내용입니다.
채점 프로그램
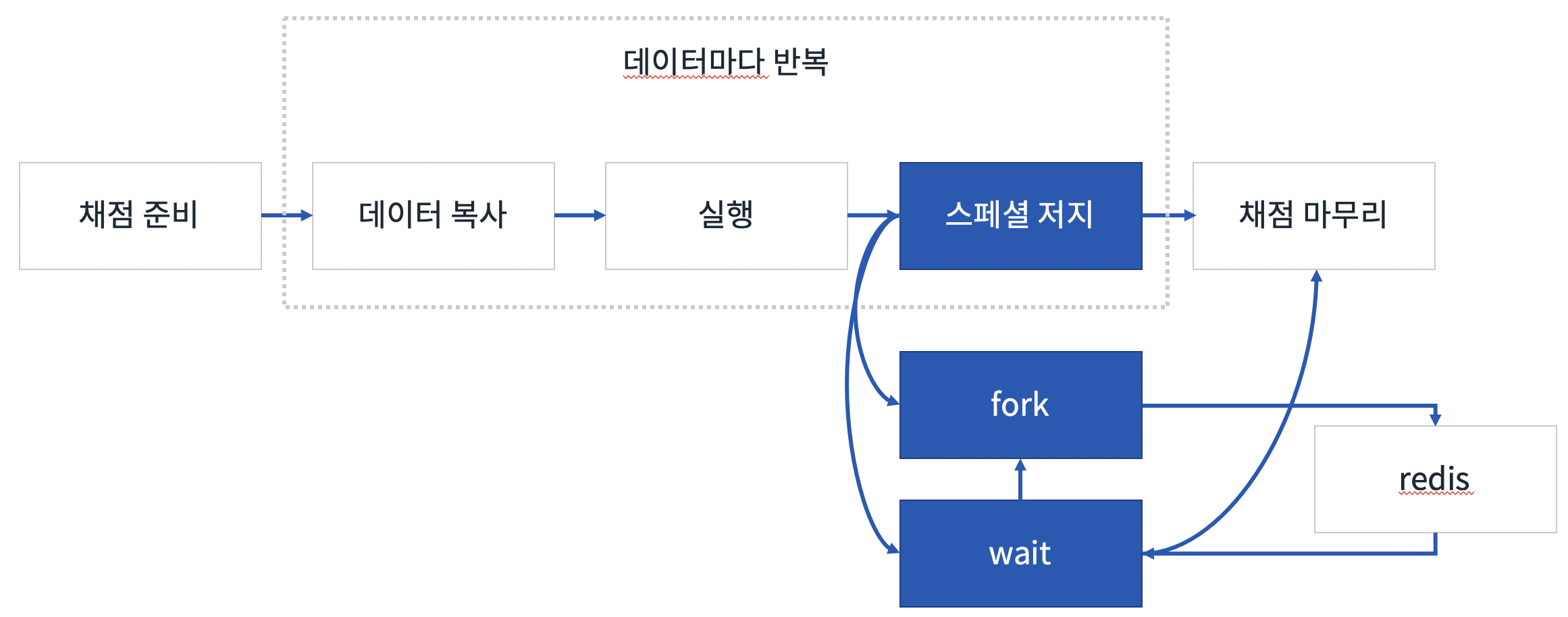
채점 프로그램의 모습을 간단히 그려보면 아래와 같습니다.

채점 프로그램은 C++로 작성했고, 실행 부분은 fork와 wait을 사용했습니다.

스페셜 저지 문제의 경우 유저의 정답을 검증하는 코드의 실행이 필요합니다. 또, 스페셜 저지의 특수한 형태인 부분 점수 문제의 경우 스페셜 저지 프로그램과 채점 프로그램간에 자료 교환이 필요했기 때문에, 아래와 같이 redis를 이용해 점수를 주고 받았습니다.
채점 진행 상황
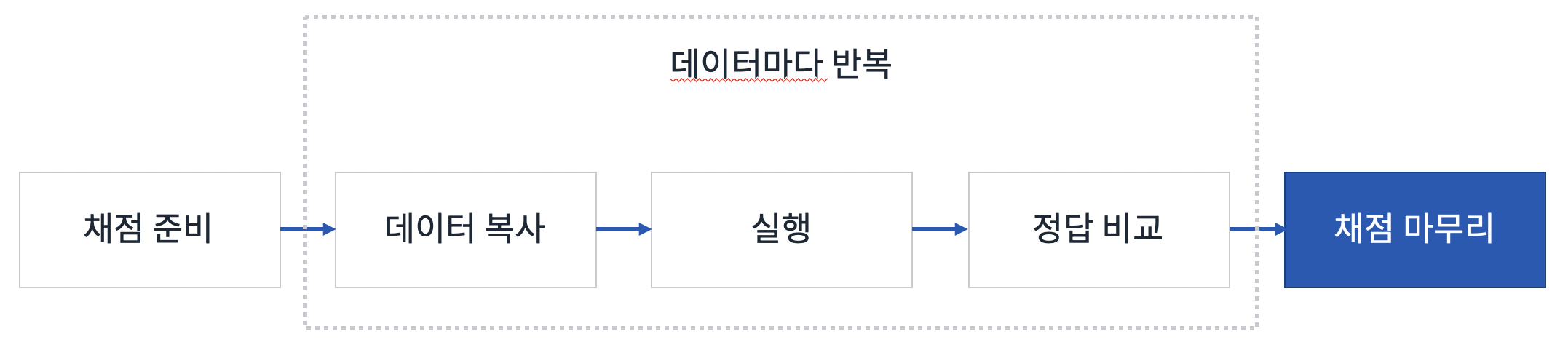
채점 진행 상황을 채점 중 (??%)와 같이 보여주기 위해서 채점의 단계가 진행될때마다 진행률을 업데이트 했습니다. 진행률을 업데이트 한 부분은 아래 그림과 같습니다.

예전에는 Polling 방식으로 채점 현황에서 1초마다 새로운 결과를 요청했습니다. 이 방식은 그렇게 좋은 방식이 아니라 생각되어 웹 소켓을 이용해 실시간 업데이트를 지원하기로 했습니다.
socket.io를 사용하기로 했는데, node.js 기반의 BOJ가 아니기 때문에, 적용하는 것이 조금 귀찮았습니다. 따라서, BOJ를 node.js로 다시 작성하기로 하고 결정했으나, 성능이 원하는 만큼 나오지 않아 프로젝트를 폐기했습니다.
Pusher를 사용하면 언어와 관계없이 이를 지원할 수 있다 생각되어 Pusher를 사용해 실시간 업데이트를 지원하기로 했습니다.
초반에는 C++에서 async 콜이 잘 되지 않아 (실력 부족) 채점이 매우 느렸으나, 실시간 업데이트를 별도의 스레드에서 돌려 업데이트를 매우 빠르게 할 수 있기 되었습니다.
다른 글에 Pusher와 비슷한 서비스인 Ably를 비교한 내용이 있는데, 성능의 문제로 Pusher를 사용하기로 결정했습니다.
데이터 동기화
예전 글에는 데이터 동기화 문제를 해결하기 위해서 S3를 이용하는 방향으로 업데이트한다는 내용이 있었는데, 실제로는 적용하지 않았습니다. 당시에는 AWS로 이주한지 얼마 되지 않은 상태였고, AWS와 요금 체계에 대한 이해가 부족했었습니다.
데이터의 동기화 문제는 1부 글에서 해결했고, S3 방식을 사용하지 않은 이유를 적어보면 다음과 같습니다.
- 데이터의 변경은 매우 드물게 일어난다.
- 데이터를 변경하면 재채점을 해야 한다.
- S3에서 EC2로 보내는 트래픽 비용이 비싸다.
성공/실패
BOJ에는 유저가 각 문제를 성공했는지 실패했는지 보여주는 기능이 있습니다.


성공/실패 기능을 구현하려면 “유저 U가 문제 P에 제출한 소스의 결과”를 알아야 합니다.
이를 구현하는 가장 간단한 방법은
- 전체 제출 중에서 유저 U가 문제 P에 제출한 소스의 결과를 검색
하는 것입니다.
매번 검색하는 것은 매우 느리지만, 2014년까지는 유저와 제출이 많지 않았기 때문에 괜찮은 방법이었습니다.
2015년 9월 2일
이 날은 BOJ에게는 매우 중요한 날입니다.
바로 랜덤 문제가 추가된 날입니다.
당시에는 Recaptcha 제한이 없고, 제출 10초 제한 밖에 없었기 때문에 자동 제출로 인해 제출이 매우 많이 늘어나게 되었습니다.





이제 매번 검색하는 방식이 매우 비효율적이 되어 버렸습니다.
이전에는 문제의 제출 수가 많지 않고, 한 유저가 하나의 문제에 제출한 횟수가 그렇게 많지 않았지만, 자동 제출로 인해서 매우 많아지는 현상이 벌어지게 되었습니다.
매번 검색하는 것을 막기위해 유저와 문제 사이의 N:N 관계를 정의할 UserProblem 테이블을 만들게 되었습니다. N:N 관계 구성에서 추가 테이블을 만드는 것은 지금은 기본이라 생각되지만, 당시에는 이를 알지 못했습니다.
UserProblem에는 다음을 저장하기로 했습니다.
user: 유저 아이디problem: 문제 번호solved: 성공(true), 실패(false), 시도 없음(NULL)
이제 이 정보를 언제 계산해야하는지 결정해야 합니다.
solved가 변경되는 시기는 최종 결과가 나왔을 때입니다. 따라서, 지금까지는 결과를 업데이트하고, 샌드 박스와 관련된 정리만을 담당했던 “채점 마무리”에서 UserProblem 관련 정보를 업데이트 하게 되었습니다.
맞은 사람
맞은 사람 페이지는 어떤 문제를 맞은 사람이 일정한 기준을 가지고 정렬되어 있는 페이지입니다. 한 사람이 여러 번 제출해서 맞은 경우도 있기 때문에, 중복된 결과를 모두 제외해야 합니다.

문제 P의 페이지를 만드려면 다음을 계산해야 합니다.
- 문제 P를 맞은 각 유저가 제출한 소스 중 가장 좋은 제출을 찾고
- 그 결과를 일정 기준을 가지고 정렬한다.
가장 좋은 소스의 기준과 정렬 기준은 다음과 같습니다.
- 수행 시간이 적은 것
- 메모리 사용량이 적은 것
- 코드 길이가 짧은 것
- 채점 번호가 앞서는 것
예전에는 이 페이지를 만드는 것이 큰 문제가 되지 않았지만, 이제 제출이 많아 오래 걸리게 됩니다. 따라서, 문제 P를 맞은 각 유저가 제출한 소스 중 가장 좋은 제출을 미리 계산하기로 했습니다.
UserProblem에 best_id를 추가해 가장 좋은 제출을 미리 저장하기로 했습니다.
숏코딩 페이지도 이와 비슷하게 처리하기 위해 가장 짧은 제출인 short_id도 미리 저장하기로 했습니다.
정답 비율 계산도 효율적으로 하기 위해 가장 처음으로 맞은 제출 first_id, 제출한 횟수 submit, 틀린 횟수 incorrect_try 등을 모두 저장하게 되었습니다.
예전에는 채점 마무리에 걸리는 시간을 무시해도 되는 수준이었는데, 이제는 이 시간을 무시하면 안되는 수준이 되었습니다.
채점 서버 N대
채점 서버가 N대가 되면, 1대일 때의 채점 진행 속도의 N배가 될까요?
정답은 예/아니오 둘 다 입니다.
채점 마무리가 없던 예전 방식이었으면 이론상으로 N배가 되었을 것이지만, 지금은 채점 마무리에 걸리는 시간 때문에, N배가 되지 않습니다.
채점 마무리의 쿼리는 매우 오래 걸릴 수도 있어서, DB 서버에서 병목 현상이 발생할 수 있습니다.
실제로 채점 서버를 10대 켰을 때보다 20대 켰을 때 더 채점의 진행 속도가 늦어졌습니다.
그럼 유저는 이런 반응을 하게 됩니다.
- 채점 서버 죽었어요.
실제로는 채점 서버가 죽은 것이 아니고 다음과 같은 일이 발생한 것입니다.
- 제출이 많은 문제에 제출이 몰려서 채점을 마무리하는데 오랜 시간이 걸리니 조금만 기다리면 채점이 됩니다.
유저는 채점을 기다리지 않고, 불편함을 주면 안되기 때문에 이를 개선해 위와 같은 설명을 유저한테 하는 일이 없어야 합니다.
채점 마무리는 크게 3가지로 구성되어 있습니다.

- 유저-문제 정보: 위에서 언급한
UserProblem - 유저 정보: 유저의 맞은 문제 수, 제출 횟수 등의 통계
- 문제 정보: 문제의 맞은 사람 수, 제출 횟수 등의 통계
세 가지 중 시간이 오래걸리면서 가장 중요하지 않은 것을 독립시키는 것으로 결정했습니다. 위의 세 가지 중에서 무엇이 가장 중요하지 않을까요?
- 유저-문제 정보는 매우 중요합니다. 채점 현황에서 “맞았습니다!!” 결과를 발견했는데, 문제 페이지나 목록에서 [성공]이 표시되지 않으면 버그라 생각할 수 있기 때문입니다.
- 유저 정보도 매우 중요합니다. 자신이 푼 문제의 수와 제출 횟수를 기억하는 경우가 있기 때문입니다. 또, 제출 수가 많은 유저는 거의 없습니다. (현재 BOJ에는 1명밖에 없습니다)
- 문제 정보도 중요하지만, 정확한 값인지 유저가 잘 알지 못합니다. 한 문제를 자신만 제출하는 것이 아닐 수도 있고, 그 사이에 몇 명이 제출했는지 모두 세어보는 사람이 없기 때문입니다. 하지만, 제출 수가 매우 적은 문제는 유저가 눈치챌 수 있습니다.
따라서, 문제 정보를 업데이트 하는 부분을 독립시키기로 했습니다. 또, 특정 시점에 한 사람이 많은 소스를 제출하는 것은 불가능하지만, 한 문제에 많은 소스를 내는 것은 충분히 가능합니다. 예를 들면, 대회나 스터디 등이 있습니다. 문제에 대한 정보를 독립시키면, 같은 연산을 덜 하게 되어 속도는 매우 빨라지게 됩니다.
AWS Lambda를 이용해 문제 정보를 업데이트하는 부분을 독립시키기로 했습니다.
위에서 언급한 제출 수가 매우 적은 문제의 경우 유저가 통계의 부정확함을 쉽게 눈치챌 수 있기 때문에 기준을 정하기 기준 이상인 경우만 Lambda를 이용해 업데이트하게 했습니다.
Lambda를 이용해 1부에서 언급한 crontab도 Lambda를 사용할 수 있게 되었습니다.

관리자 제출과 재채점
관리자 제출은 유저의 눈에 보이지 않고, 통계에도 포함되지 않는 것이 좋습니다. 관리자는 테스트를 위해 2-30개의 소스를 한 번에 제출하는 경우가 많습니다. 이런 경우에 모든 채점 서버가 관리자 제출을 채점하고 있다면, 유저는 이런 반응을 보입니다.
- 채점 서버 죽었어요.
그럼 관리자는 설명해야 합니다.
- 눈에 보이지 않는 관리자 제출을 채점하는 중이니 조금 기다리면 채점이 됩니다.
설명을 하는 것보다 설명하는 상황을 만들지 않는 것이 좋기 때문에, 큐를 다음과 같이 두 개로 나누기로 결정했습니다.
- 일반 큐
- 관리자 큐
재채점은 어떤 큐를 쓰는 것이 좋을까요? 일반 큐를 쓰면 재채점이 모두 완료될 때까지 유저는 기다려야 합니다. 관리자 큐를 쓰면 관리자가 기다려야 합니다. 기다리는 것은 좋지 않고, 채점 속도의 관점에서 재채점의 채점 우선순위는 매우 낮기 때문에 재채점 큐를 새로 추가하기로 결정했습니다.
- 일반 큐
- 관리자 큐
- 재채점 큐
만약, 모든 채점 서버가 재채점 큐에 있는 제출을 채점 하고 있고, 마침 그 소스가 모두 매우 오래걸리는 소스라면 어떤 일이 벌어질까요?
- 유저: 채점 서버 죽었어요.
관리자는 또 설명해야 합니다.
- 시간이 오래 걸리는 제출을 재채점하는 중이니 조금 기다리면 채점이 됩니다.
결국 채점 프로그램이 어떤 채점 큐를 사용할지 결정할 수 있게 업데이트를 해 위와 같은 일을 모두 해결하게 되었습니다.
채점 우선 순위
위에서 큐를 나누어 채점의 우선 순위를 정한 것을 볼 수 있었습니다. BOJ는 알고리즘 문제를 푸는 곳이고, 랜덤 문제는 알고리즘 문제가 아니기 때문에, 채점의 우선 순위를 낮추기로 결정했습니다. 처음에는 관리자 큐에 넣었는데, 관리자가 기다리는 현상과 BOJ Stack의 제출(뒤에서 설명합니다)이 기다리는 현상이 발생해 재채점 큐로 모두 넣어버렸습니다.
3부
3부에서는 다시 웹에 대해서 알아봅니다.

“BOJ 10 Years 2부”에 대한 답글 2개